scRAPID-web - Tutorial
scRAPID-web is a web-based platform offering a user-friendly interface for scRAPID, a computational pipeline for the prediction of protein-RNA interactions from single-cell RNA-sequencing data.
Home page
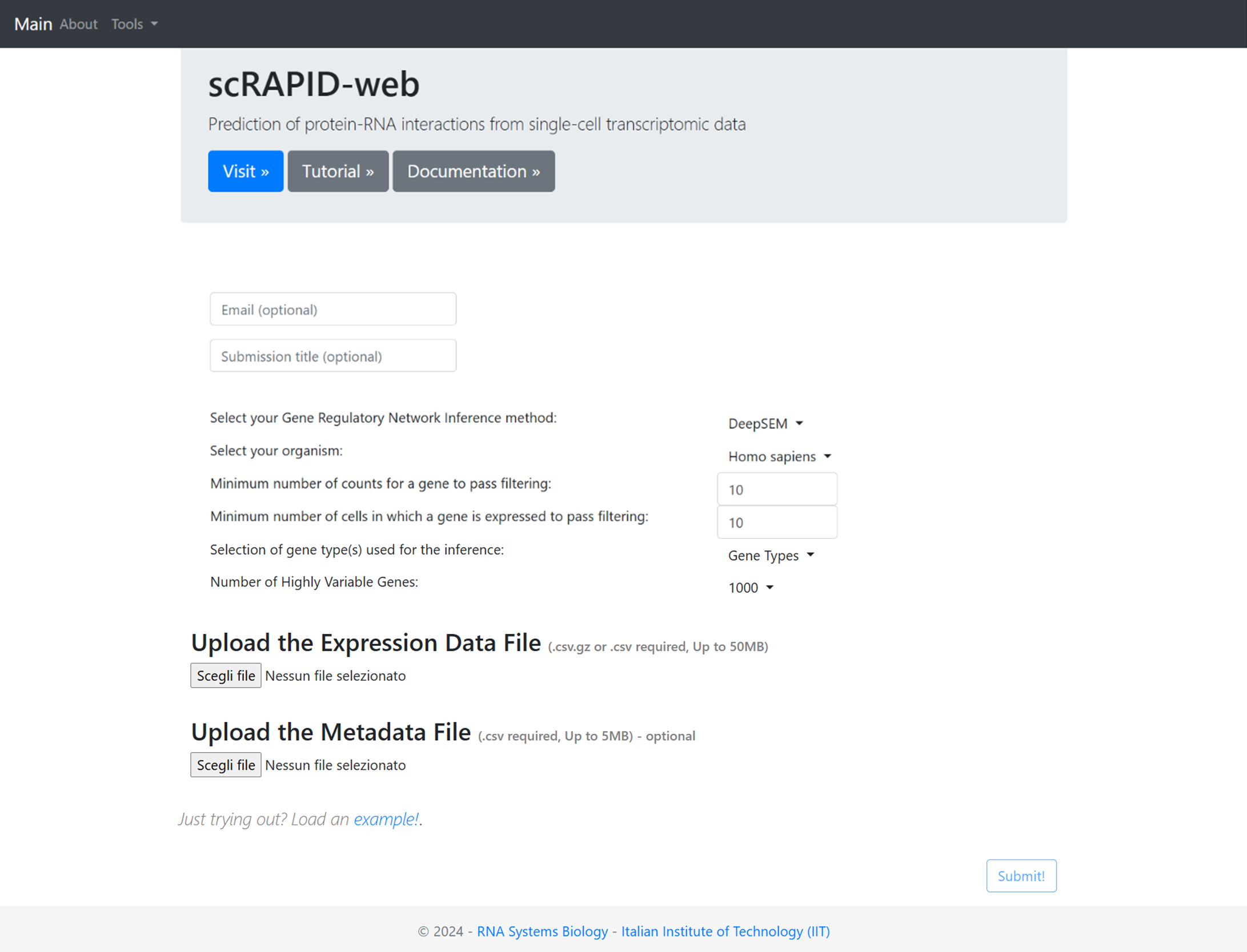
On the web server homepage, users can provide their email and a submission title to receive a notification with a link to the results upon job completion. The user can choose between different options related to the GRN inference algorithm, organism, pre-processing parameters of the dataset and the types of genes to include in the analysis. We describe the available options in detail below.
GRN Inference method
The user can choose between 3 GRN inference algorithms:
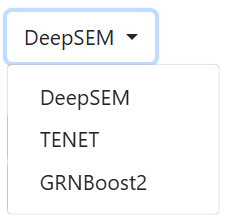
- DeepSEM (default) uses a neural network implementation of the Structural Equation Model to infer the GRN.
- TENET employs transfer entropy to infer directed causal interactions along pseudotime.
- GRNBoost2 is a gradient-boosting regression model. We suggest its usage for the prediction of RBP-RBP interactions, selecting 3000 HVGs.
DeepSEM and TENET are the most accurate algorithms for the prediction of protein-RNA interactions.
Organism
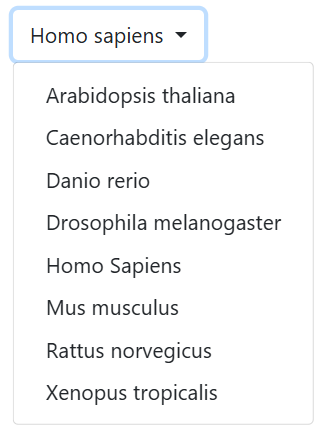
The user can choose among eight different organisms: Arabidopsis Thaliana, Caenorhabditis Elegans, Danio Rerio, Drosophila Melanogaster, Homo Sapiens, Mus Musculus, Rattus Norvegicus, Xenopus Tropicalis. The default organism is Homo Sapiens.
Minimum number of counts for a gene to pass filtering
Those genes whose count values sum up to a value lower than this threshold are filtered out. The user can choose between 10, (add the other value that can be chosen). The default is 10 counts.
Minimum number of cells in which a gene is expressed to pass filtering
Those genes which are expressed (count ≥ 1) in a number of cells lower than this threshold are filtered out. The user has the possibility to choose between 10, (add the other value that can be chosen). The default is 10 cells.
Selection of gene type(s) used for the inference
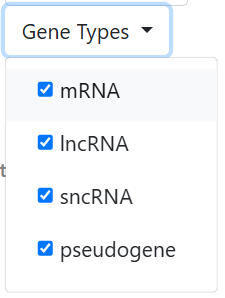
Selection of the gene type(s) on which the scRAPID pipeline will run. The expression heatmap will be filtered to include only genes belonging to these gene types and those coding for RBPs. It is possible to choose a single category or multiple ones: mRNA, lncRNA, sncRNA, pseudogene. By default all gene types are selected.
Number of Highly Variable Genes
The user can choose between 1000, 2000 or 3000 top HVGs (genes that show significant variability in their expression levels across different cells in the dataset). The list of genes used for the inference is the union of these HVGs with all the highly variable RBPs. The default is 1000 HVGs.

Alternatively, the user can upload a custom gene list, which is then joined with the highly variable RBPs for GRN inference. The file should be a text file with one gene ID per line.

Upload the expression data file
This file contains the gene expression matrix that will be used for the inference. The file should follow a comma-separated format (.csv extension), with genes in rows and cells in columns. Values should represent Unique Molecular Identifier (UMI) or raw read counts. The first row must contain cell identifiers (e.g., barcodes), and the first column should list gene names or gene IDs. In addition to Ensembl Gene IDs, scRAPID-web accepts gene identifiers from various categories, including Gene Name, NCBI gene/Entrezgene accession, NCBI gene/Entrezgene ID, GenBank ID, Xenbase ID and ZFIN ID. These identifiers are automatically mapped to Ensembl Gene IDs during the analysis. Due to the size limit of 50 MB, we recommend uploading files compressed using gzip (.csv.gz extension). For assistance with compression, refer to FreeCodeCamp Guide or CSV Compressor. Users wishing to analyze larger datasets can do so by running scRAPID locally, where no fixed limits on input size are imposed beyond available computational resources; the full toolset is available at https://github.com/tartaglialabIIT/scRAPID.
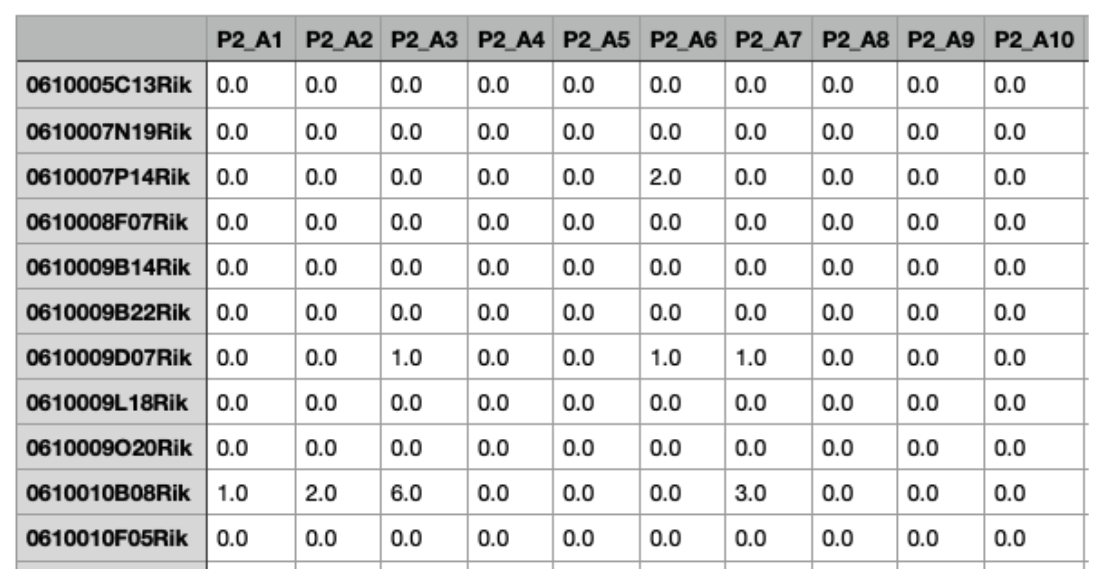
Upload the Metadata File
The cell metadata file is mandatory when the TENET algorithm is chosen for GRN inference, while it is optional if GRNBoost2 or DeepSEM are chosen. It should be uploaded in a comma separated (.csv) format, with a size limit of 5 MB. The first row should contain the header. The first column should list cell identifiers corresponding to those in the gene expression matrix. The other columns should represent categorical variables, such as differentiation time points and/or cell types.
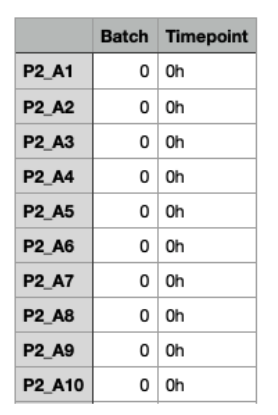

After loading the metadata file, the user can choose the column that will be used to filter cells.
After this column is selected, the user will be allowed to select values from this column (all values are selected by default). Only cells corresponding to these values will be used for the analysis.


When the user chooses the TENET algorithm, a second option appears for the metadata, that allows the user to select a metadata column that will be used to colour cells in the diffusion map.
Interpreting the output
After the job is submitted using the “Submit!” button, the result page will be reloaded every six seconds until the results are available. Real time progress updates show the processing stage to the user. If the submission fails, detailed error logs are returned to the user. Runtimes for an example dataset for the three GRN inference algorithms and different numbers of HVGs are provided in the Documentation.
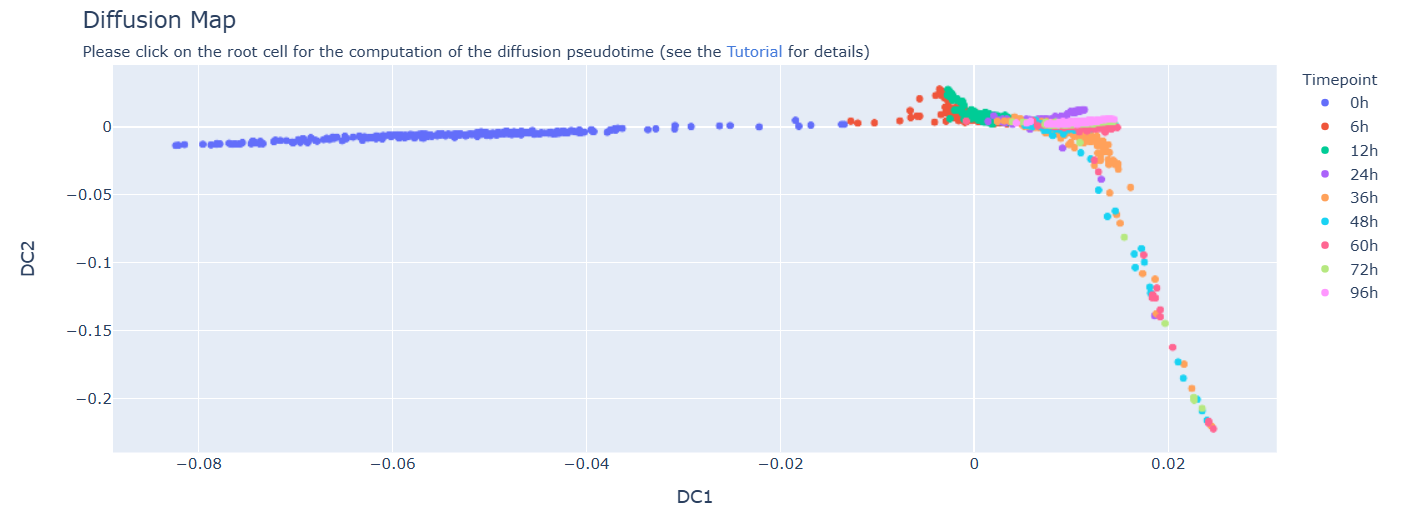
If the TENET algorithm is chosen by the user, there is an intermediate step before the job is submitted, needed for the computation of the diffusion pseudotime.
A page with an interactive plot of the first two components of a Diffusion map will appear, showing the cells colored according to the categories present in the cell metadata column previously chosen by the user. The user should click on the cell that represents the root for the computation of the diffusion pseudotime. In the example plot below, the metadata categories represent differentiation time points of mouse embryonic stem cells (Semrau, Stefan et al. “Dynamics of lineage commitment revealed by single-cell transcriptomics of differentiating embryonic stem cells.). In this case, the root cell belongs to the "0h" time point (blue cells) and should be chosen as the cell at the edge of the differentiation trajectory, specifically the one with the minimum DC1 value.
After the selection of the root cell, a pop-up message will ask the user to confirm the selection. If the user does not confirm, the selection can be repeated.
The job is then submitted and the GRN inference is run on the set of genes chosen by the user (HVGs or a custom gene list) joined with the highly variable RBPs. All the steps of the scRAPID pipeline (catRAPID-based filtering of the protein-RNA interactions, prediction of hub RBPs and hub RNAs, prediction of RBP–RBP interactions) are performed and the final output page is generated. Upon completion, the final output page is generated, featuring a series of detailed tables and a network visualization at the bottom, which are described in the following sections. The network and the RBP–RBP interaction table are not generated when TENET is used. It is strongly advised to save the results for future reference since they will remain on the server for two weeks.
Result tables
At the top of the output page, a table menu allows access to several tables reporting the results of the scRAPID pipeline. Each table can be downloaded in CSV format by clicking on the “Get table” button. The RBP-RNA interactions table can also be downloaded as a JSON object formatted for Cytoscape. To open the file in Excel, create a new blank workbook, navigate to the Data tab, and select Get External Data > From Text/CSV. Users can sort tables based on column values and search for specific genes.
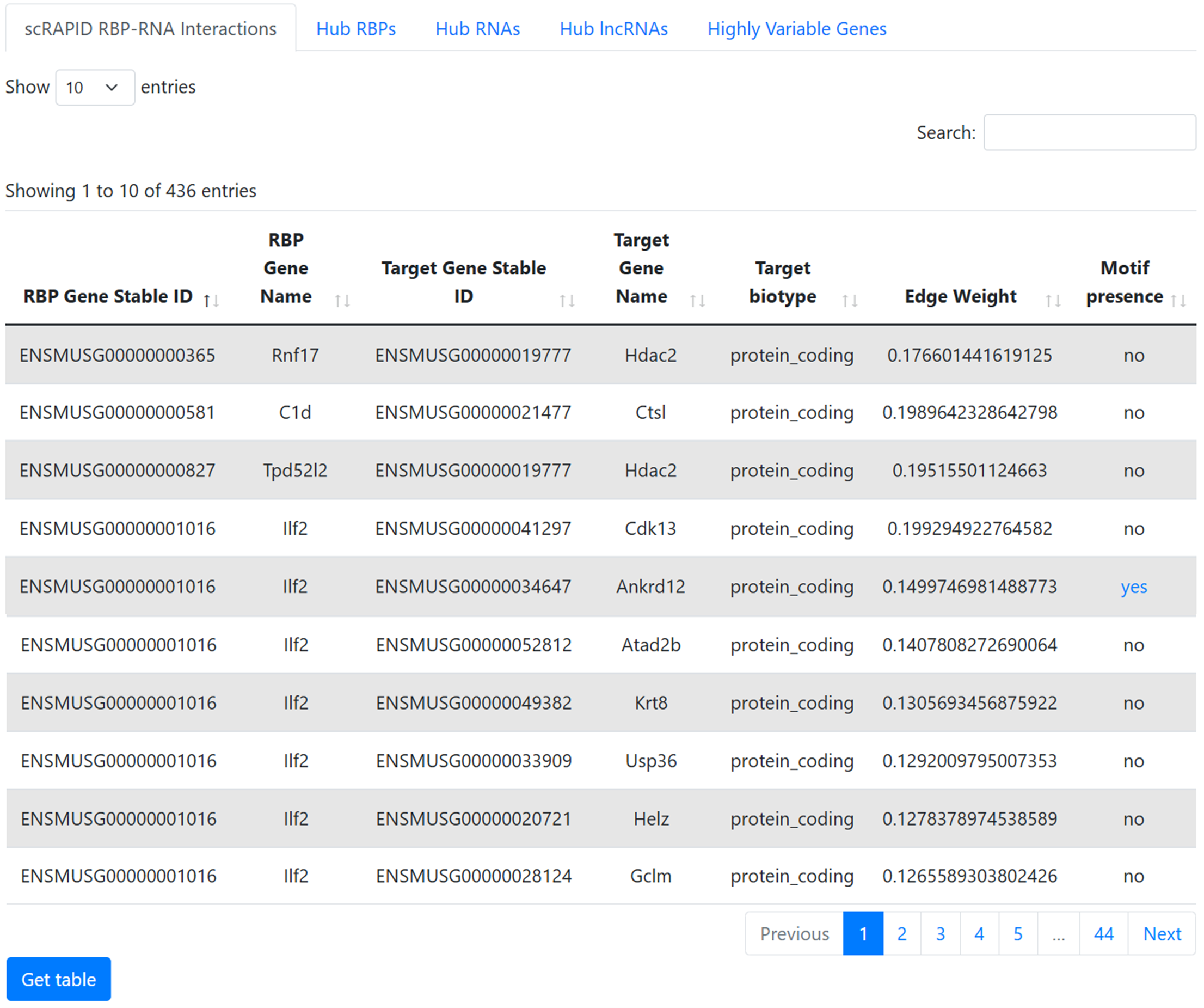
scRAPID RBP-RNA Interactions
This table represents the list of inferred protein-RNA interactions that passed the catRAPID-based filter.
The first column displays the Ensembl gene ID of the RBP, while the second shows its gene symbol. The third and fourth columns provide the same information for the target, while the fifth column reports its Ensembl transcript ID. The sixth column indicates the biotype of the target, the seventh shows the edge weight (the score assigned to the interaction by the inference algorithm), and the last column indicates whether RBP-specific motifs were identified within the target sequences. When present, “direct” denotes motifs experimentally determined for that RBP, whereas “assigned” indicates motifs assigned to the RBP based on sequence similarity. Clicking on these entries opens a pop-up window showing the motif occurrences within the target transcript. If no motif is identified, the entry “-” is displayed.

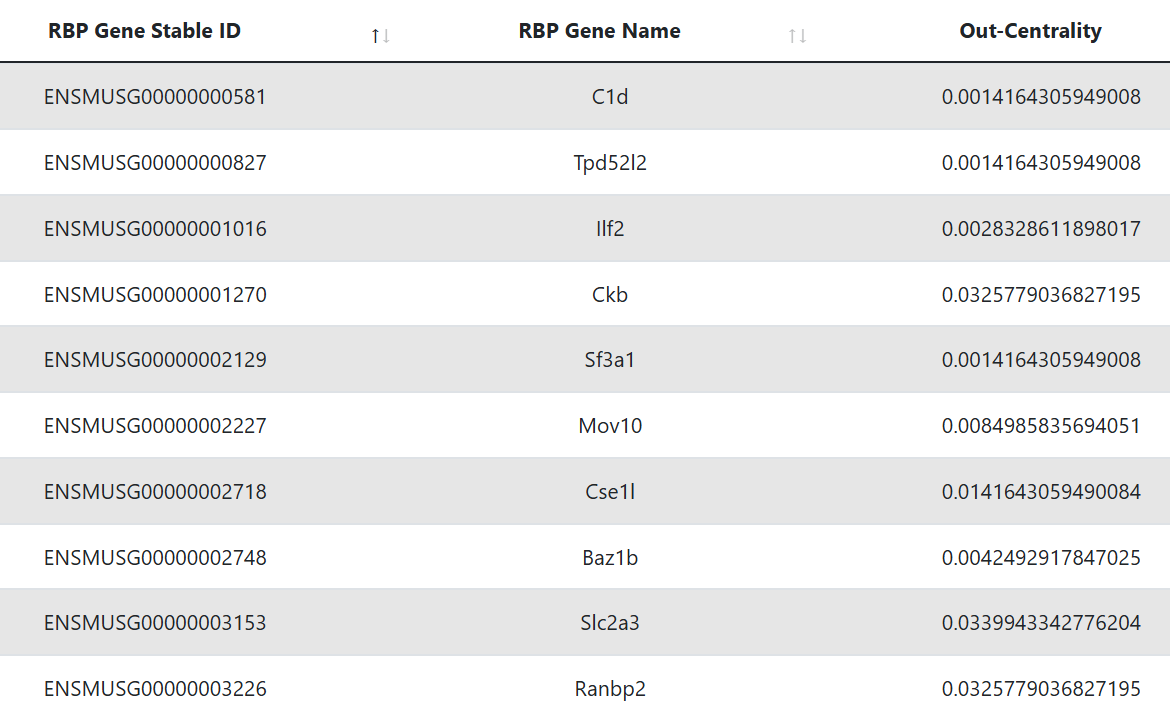
Hub RBPs
This table represents the RBPs that are identified as hubs. The first column displays the Ensembl gene ID of the RBP, while the second shows its gene symbol. The third column reports the out-degree centrality, which is the fraction of nodes its outgoing edges are connected to.
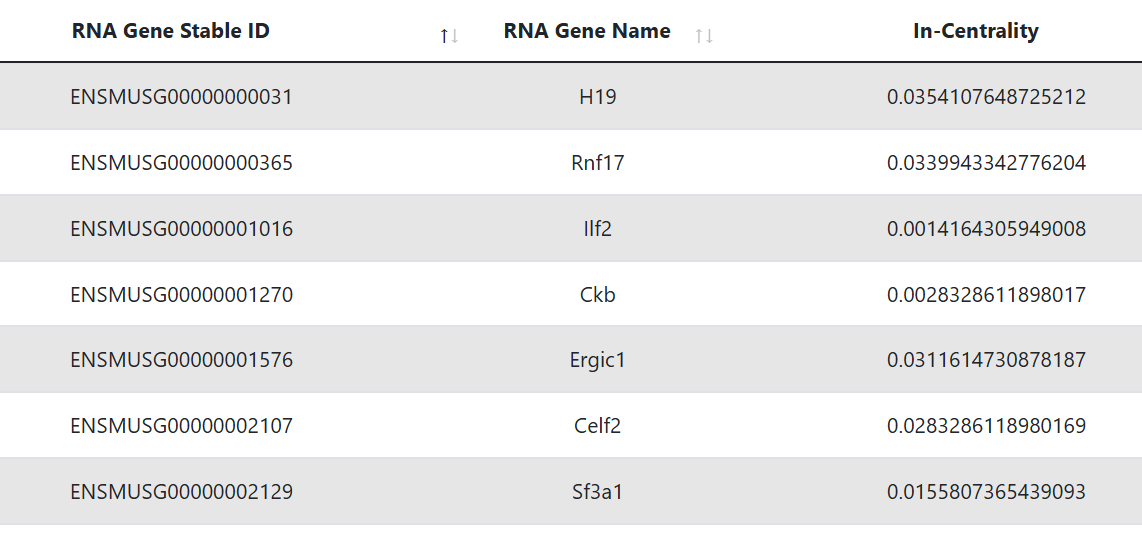
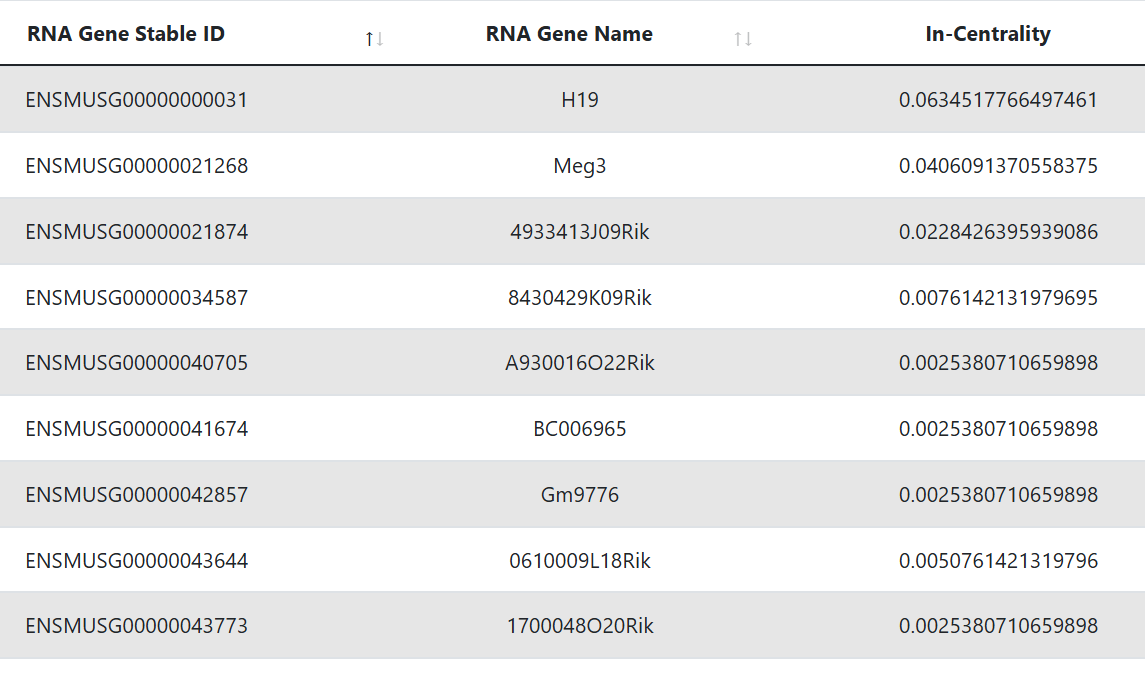
Hub RNAs
This table represents the targets that are identified as hubs. The first and second column display the Ensembl gene ID and Ensembl Transcript ID of the RNA, while the third shows its gene symbol. The last column reports the in-degree centrality, which is the fraction of nodes its incoming edges are connected to.
Hub lncRNAs
This table is shown only when the lncRNA biotype is selected. It represents the lncRNA targets that are identified as hubs. The first and second column display the Ensembl gene ID and Ensembl Transcript ID of the RNA, while the third shows its gene symbol. The third column reports the in-degree centrality, which is the fraction of nodes its incoming edges are connected to.
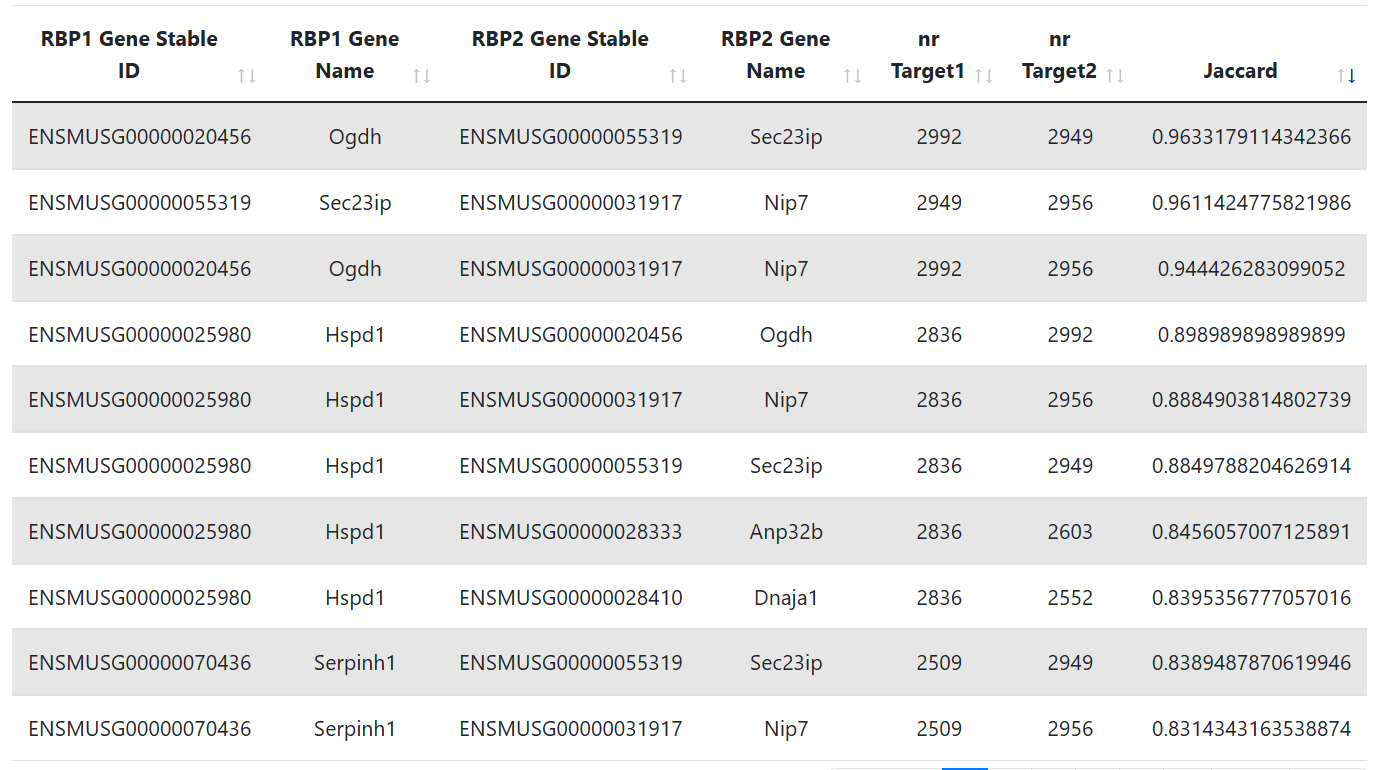
RBP Co-Interactions
This table lists RBP-RBP pairs, along with the number of targets from the inferred GRN (see the Documentation for more details) and the Jaccard coefficient quantifying target overlap.
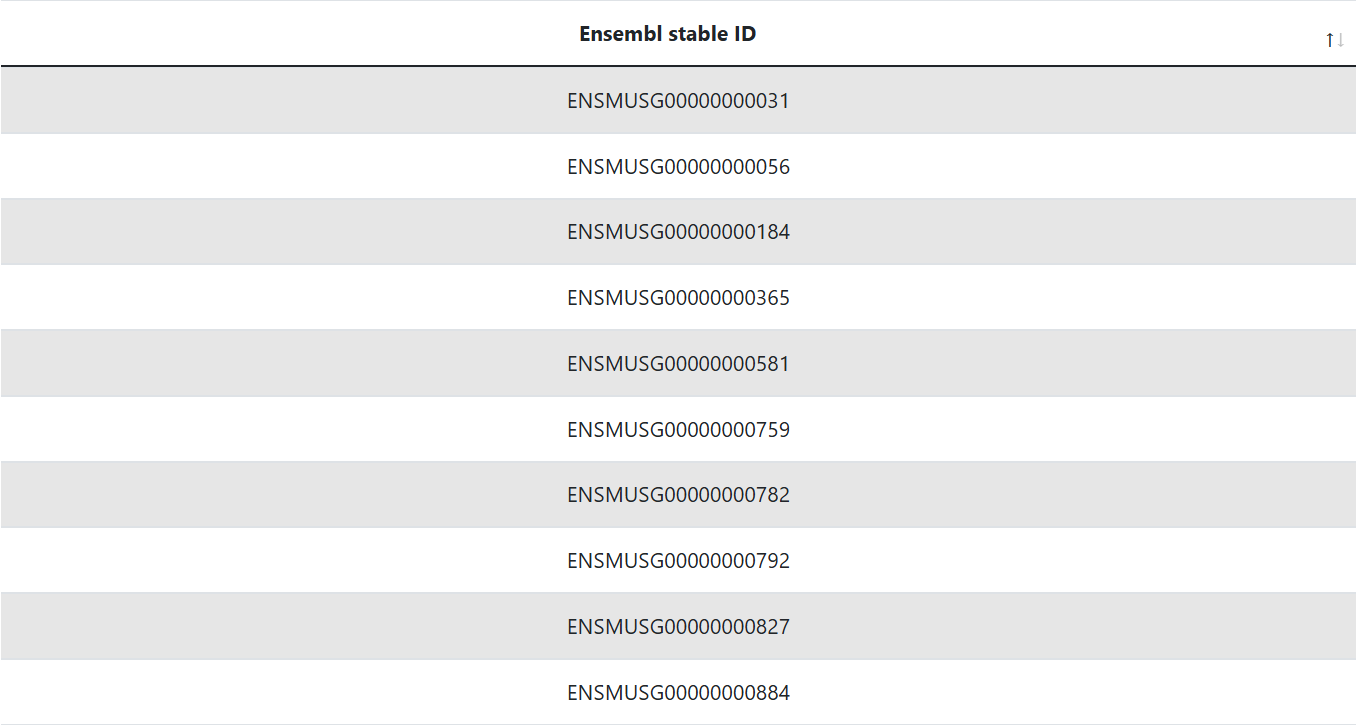
GRN Inference Genes
This table lists the Inference genes used for network inference. Depending on the user input, these genes are either the top variable genes (topHVGs) or the user provided list of genes combined with all the highly variable RBPs
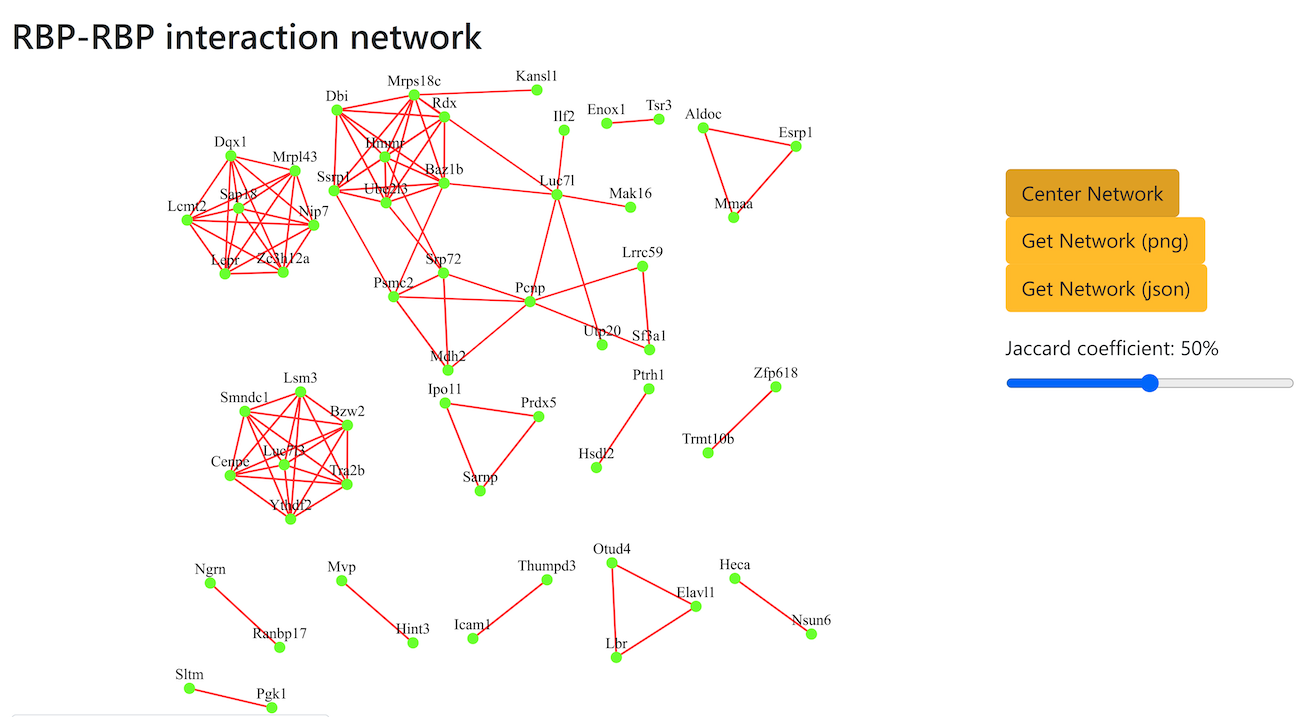
RBP-RBP interaction network
The network shows the interactions between RBPs inferred based on their predicted shared targets. Users can interact with the network by clicking and dragging nodes or zooming in on specific areas. Connectivity can be adjusted by modifying the Jaccard coefficient threshold, enabling the identification of potential protein complexes. Additionally, the network can be downloaded as a PNG image or a Cytoscape-compatible JSON file. Please reload the page if the network is not displayed.
In the JSON file, each RBP (node) is annotated with:
- nr_Tgt: the number of RNA targets associated with the RBP, and
- nr_Tgt_norm: the min-max normalized version of nr_Tgt in the [0, 1] range.
- degree: how many times the RBP appears across all pairs.
- degree_norm: the min-max normalized version of degree in the [0, 1] range.
Moreover, each RBP–RBP pair (edge) is assigned an EdgeWeight which corresponds to the Jaccard coefficient measuring the similarity of their target RNA sets.
File Checksums
The "File Checksums" tab provides MD5 checksums for all downloadable CSV files generated by the scRAPID pipeline. This allows users to verify the integrity of downloaded files by comparing the MD5 checksum of their local file with the checksum displayed in the table. The checksums are automatically calculated when the task completes successfully and are displayed in a simple two-column table: one column showing the filename and another showing the corresponding MD5 checksum. This feature is particularly useful for ensuring data integrity when downloading large files or when sharing results with collaborators.